Combien de pages pour une thèse ou un mémoire?
 Si vous avez déjà rédigé un mémoire de maîtrise ou une thèse de doctorat, vous vous êtes certainement posé ces questions :
Si vous avez déjà rédigé un mémoire de maîtrise ou une thèse de doctorat, vous vous êtes certainement posé ces questions :
- Combien de pages pondre?
- Est-ce que j’en fais suffisamment?
- Est-ce que j’en fais trop?
- Et puis, quelle est la longueur moyenne d’un mémoire ou d’une thèse?
En googlant ces questions, j’ai été étonné du peu de réponses que j’obtenais. Wikipédia affirme qu’au Canada, « Master’s theses are approximately one hundred pages. PhD theses are usually over two hundred pages. » On y indique aussi que, dans les universités francophones, les mémoires de maîtrise font généralement autour de 75 pages et les thèses de doctorat dépassent 100 pages. Voilà qui est bien vague.
Les universités du Québec font bien quelques recommandations à leurs étudiants :
- McGill invite ceux du deuxième cycle à ne pas dépasser les 100 pages.
- En sociologie, à l’UQAM, on leur demande de viser 120 pages.
- Aux HEC, on dit que « le mémoire ne devrait pas dépasser 150 pages ».
- L’Université du Québec à Trois-Rivières, de son côté, suggère à ses doctorants en administration de rédiger « entre 200 et 400 pages ».
 Mais combien de pages livrent-ils et elles, dans les faits, au terme de leurs études? Aucune donnée là-dessus. On ne sait rien de la longueur moyenne des mémoires et thèses québécoises.
Mais combien de pages livrent-ils et elles, dans les faits, au terme de leurs études? Aucune donnée là-dessus. On ne sait rien de la longueur moyenne des mémoires et thèses québécoises.
Dans le reste du monde, les chiffres sont aussi rares. Le chercheur Marcus Beck a fait, à l’aide du langage R, un exercice qui semble unique. Il a récolté des données sur près de 4000 thèses et mémoires publiés à l’Université du Minnesota depuis 2007. Il en a produit de très intéressantes visualisations. Elles permettent notamment de voir la longueur des thèses ou mémoires en fonction du département où ils ont été publiés. Mais ce travail reste confiné à une seule université.
Ces dernières semaines, j’ai donc tenté de combler l’absence de données sur ces questions. Je présente mes résultats ci-dessous, avec leurs qualités, mais aussi leurs limites.
Je vends le punch immédiatement. Au Québec :
Le mémoire de maîtrise moyen compte 133,3 pages.
La thèse de doctorat, quant à elle, fait en moyenne 251,3 pages.
Pour arriver à ces chiffres, j’ai procédé en trois étapes, la démarche classique du journalisme informatique, ou « de données ».
Étape 1 – Moissonnage
Toutes les universités de la province ont leur dépôt institutionnel dans lequel on trouve, entre autres, les thèses et mémoires des étudiants de l’institution. Voici les adresses de ces dépôts pour les 18 universités du Québec et le nombre de documents que j’ai pu aller moissonner dans chacun :
[wpsm_comparison_table id= »1″ class= » »]
Certaines universités sont marquées par un X rouge dans le tableau ci-dessus. Ces universités ont été exclues de mon échantillon parce qu’elles comptent trop peu de documents dans leur dépôt. J’ai placé arbitrairement la limite à 125 thèses ou doctorats. Ainsi, dans chacune des 13 universités qui restent, j’ai pu aller chercher entre 400 et près de 10 000 documents, pour un grand total qui dépasse les 55 000!
Maintenant, tous les dépôts universitaires ne sont pas moissonnables de la même manière. Je les ai divisés en trois catégories: les faciles, les sportifs et les exaspérants.
- La plupart, heureusement, sont dans la première catégorie. « Chercheur-friendly », ils permettent de télécharger nos résultats de recherche en formats XML, JSON, CSV, etc. C’est le cas des sites de l’Université Concordia, de l’INRS et de plusieurs composantes de l’Université du Québec. On trouve parfois, dans ces résultats, des métadonnées sur le nombre de pages de la thèse ou du mémoire. Dans ces cas, c’est du bonbon.
- Plusieurs autres dépôts font partie de la deuxième catégorie. Ils ne donnent pas leur contenu tout cuit dans le bec. Il faut écrire un script de moissonnage pour effectuer l’extraction désirée. Mais c’est relativement simple. Chaque thèse ou mémoire dispose d’un numéro de code qu’on retrouve dans un permalien, un URL unique qui ne change pas, ce qui facilite le travail. À l’Université de Montréal, par exemple, la thèse #6474 est repérable par l’URL suivant : http://hdl.handle.net/1866/6474.
- Reste la troisième catégorie : les dépôts qui font suer le moissonneur de données. Les HEC, l’Université Laval et McGill ont mérité d’en faire partie pour différentes raisons. HEC et Laval, tout d’abord, s’arrangent pour que l’URL du site ne change pas lorsqu’on accède aux thèses. Cela rend le moissonnage plus difficile et m’a obligé à recourir à selenium pour recueillir les données qui m’intéressaient. McGill, pour sa part, a une section que j’ai découverte par hasard qui contient les URL de toutes ses thèses et mémoires. Les recueillir est un jeu d’enfant. Il y en a 43 688! Mais voilà : le site web de McGill refuse les connections répétées. J’ai utilisé tous les subterfuges à ma portée : implanter un sleep aléatoire, me connecter via des proxys. À bout de patience, après des jours à écrire plusieurs scripts pour tenter d’autres parades, j’ai lancé la serviette et je me suis dit que les quelque 5 000 documents que j’avais recueillis jusqu’à maintenant constituaient un échantillon représentatif des thèses et mémoires publiés par cette université.
 J’aurais pu, bien entendu, m’adresser à chaque université pour leur demander les métadonnées relatives à leurs thèses et mémoires. Mais je voulais atteindre un autre objectif en faisant tout cet exercice : réapprendre python. Ces dernières années, inspiré par Dan Nguyen, j’avais pris l’habitude d’utiliser ruby comme langage de script. Mais avec le temps (et avec l’insistance de certains collègues), j’ai bien compris que python était beaucoup mieux pourvu en modules complémentaires (bibliothèques) et possédait une communauté beaucoup plus vivante. C’est, depuis septembre dernier, le langage que je montre à mes étudiants.
J’aurais pu, bien entendu, m’adresser à chaque université pour leur demander les métadonnées relatives à leurs thèses et mémoires. Mais je voulais atteindre un autre objectif en faisant tout cet exercice : réapprendre python. Ces dernières années, inspiré par Dan Nguyen, j’avais pris l’habitude d’utiliser ruby comme langage de script. Mais avec le temps (et avec l’insistance de certains collègues), j’ai bien compris que python était beaucoup mieux pourvu en modules complémentaires (bibliothèques) et possédait une communauté beaucoup plus vivante. C’est, depuis septembre dernier, le langage que je montre à mes étudiants.
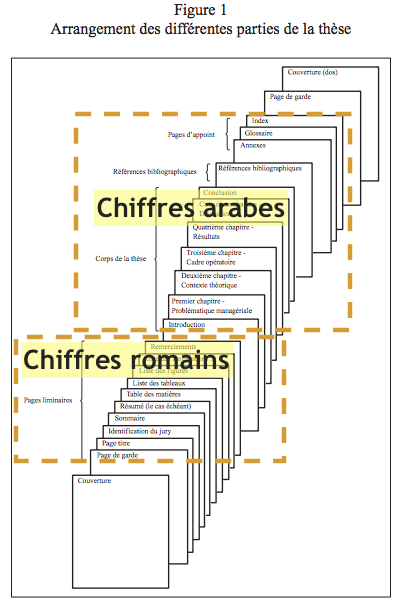
Structure d’une thèse. Adaptation d’un document de l’UQTR (https://oraprdnt.uqtr.uquebec.ca/pls/public/docs/GSC1543/F72008302_DBA.pdf)
Maintenant, comme le montre l’illustration ci-dessus, une thèse (ou un mémoire) est composée de nombreuses sections. Les premières, qu’on appelle pages liminaires, sont paginées en nombres romains. Tout le reste l’est en nombres arabes.
Cela fait que les métadonnées relatives au nombre de pages avaient souvent l’aspect suivant (exemple tiré de Concordia) :
xxi, 204 leaves : ill. ; 29 cm.
 C’est en fait une description de la thèse, avec le nombre de pages liminaires d’abord, puis le nombre de feuillets. Il n’y a pas, en python, de fonction qui permette de convertir automatiquement des nombres romains en nombres entiers. J’ai trouvé quelque part un court script qui le fait et je l’ai adapté à mes besoins. Après un passage dans ma moulinette, le nombre de pages de l’exemple montré ci-haut (XXI pages liminaires + 204 feuillets) était donc de 225.
C’est en fait une description de la thèse, avec le nombre de pages liminaires d’abord, puis le nombre de feuillets. Il n’y a pas, en python, de fonction qui permette de convertir automatiquement des nombres romains en nombres entiers. J’ai trouvé quelque part un court script qui le fait et je l’ai adapté à mes besoins. Après un passage dans ma moulinette, le nombre de pages de l’exemple montré ci-haut (XXI pages liminaires + 204 feuillets) était donc de 225.
Le plus souvent, toutefois, le nombre de pages n’était pas facilement disponible. Ce que j’ai dû faire, donc, c’est de télécharger chacune de ces thèses, si elle était disponible en format PDF, puis de compter le nombre de pages qu’elle contient.
Évidemment, je n’ai pas compté manuellement le nombre de pages. Je me suis plutôt servi de la bibliothèque PyPDF2. Une fois le fichier téléchargé et son nom placé dans la variable nomFichier, trois lignes de code suffisaient pour en extraire le nombre de pages.
Je l’ouvrais et plaçais le contenu dans une autre variable que j’ai appelée fich :
fich = open(nomFichier, "rb")
Ensuite, je demandais à PyPDF2 d’ouvrir fich et d’en placer le contenu dans une autre variable que j’ai appelée objet :
objet = PyPDF2.PdfFileReader(fich)
Enfin, il suffisait d’invoquer la méthode getNumPages() pour obtenir le nombre de pages de cet objet (qui correspond au nombre de pages du document initial) et d’imprimer le résultat :
print("{0} fait {1} pages".format(nomFichier,objet.getNumPages()))
Le nombre de pages d’un document PDF ne correspond pas toujours au nombre de pages réel de la thèse ou du mémoire, car les universités ajoutent parfois une ou quelques pages de garde au début du document. Pas toujours.
Il aurait cependant été fastidieux de vérifier chacun des PDF pour tenir compte de ces ajouts, dans les cas où il y en a. Je ne l’ai donc pas fait. Cela ajoute peut-être entre une demie et une page aux moyennes indiquées en début de billet.
Ç’a beau se faire automatiquement, mais télécharger plus de cinquante mille PDF de près de 200 pages chacun, en moyenne, a été long en saperlipopette, sans compter que certains fichiers corrompus ont régulièrement fait planter mes scripts! Ce sont ainsi 586 620 982 544 octets qui sont passés dans mon modem, plus d’un demi-téra! Et il y avait encore du travail à faire!
Étape 2 – Nettoyage et analyse
 Les données, on le sait, ça peut être sale. Les responsables des dépôts institutionnels font un excellent travail pour que leurs données soient fiables. J’ai malgré tout trouvé quelques erreurs (en plus des fichiers corrompus mentionnés ci-dessus).
Les données, on le sait, ça peut être sale. Les responsables des dépôts institutionnels font un excellent travail pour que leurs données soient fiables. J’ai malgré tout trouvé quelques erreurs (en plus des fichiers corrompus mentionnés ci-dessus).
Juste deux exemples. Selon sa fiche signalétique, ce doctorat fait deux pages seulement. En allant chercher le PDF, cependant, on constate qu’il en compte en réalité 529. À l’inverse, l’auteur de ce mémoire aurait pondu 1136 pages! En le téléchargeant, cependant, on voit bien que la personne qui a entré les métadonnées a appuyé deux fois sur « 1 » par mégarde.
Valeurs extrêmes
Mais même lorsqu’il n’y a pas d’erreurs, il faut effectuer un nettoyage. C’est ainsi que j’ai vérifié toutes les valeurs extrêmes.
En commençant par les documents très courts, je me suis rendu compte qu’il était difficile de comparer des mémoires ou des thèses «classiques» avec certains types de documents généralement plus courts, comme des mémoires ou des thèses rédigés sous forme d’article(s) scientifique(s). Si les thèses de doctorat par cumul de publication sont de plus en plus reconnues, voire la norme dans bien des disciplines (Niven et Grant [2010] ne considèrent pas qu’il s’agit d’une solution facile, je les ai donc conservées), j’ai exclu les mémoires de maîtrise rédigés sous la forme d’un article scientifique, car je n’ai pas trouvé de documentation attestant du même degré de reconnaissance qu’au troisième cycle.
J’ai également écarté les essais de troisième cycle (comme celui-ci) ou (après le commentaire de M. Carbonneau, ci-dessous, les mémoires doctoraux, comme celui-ci) généralement plus courts qu’une thèse en bonne et due forme.
En outre, les PDF de plusieurs thèses ou mémoires très courts ne comprennent en fait que la table des matières. C’est le cas, par exemple, de ce doctorat en musique. Le document PDF ne compte que 11 pages seulement. Mais quand l’on ouvre et qu’on lit la table des matières, on constate qu’il devrait en réalité faire plus de 78 pages. En fait, le PDF ne contient que les pages liminaires du doctorat. Où est le reste? Mystère (résolu grâce au commentaire de Mme Vézina, ci-dessous). J’ai ouvert tous les documents faisant moins de 50 pages et corrigé les données lorsque c’était possible, sinon, j’ai éliminé ces entrées.
Cette vérification a permis d’identifier :
- La plus courte thèse du Québec. Publiée en 2002, par un doctorant en mathématiques de l’Université de Sherbrooke, elle s’intitule Le plan d’échantillonnage à réponse partielle (PAST) (Partial Answer Sampling Technique) et compte 46 pages seulement!
- Le plus court mémoire du Québec. Toujours en mathématiques (actuariat), mais publié en 1994 à Concordia, le plus court mémoire de mon échantillon ne compte que 19 pages! Son titre est Bivariate Lifetime Distributions.
À l’autre extrême, 10 doctorats, dans mon échantillon, dépassent le millier de pages! Pauvres collègues!
En fait, si des thèses et des mémoires comptent un très grand nombre de pages, c’est généralement parce qu’ils contiennent de volumineux annexes. Les annexes font toutefois partie intégrante de ces documents. Il n’était donc pas question de les exclure.
J’ai quand même systématiquement vérifié les 10 plus longues thèses et les 10 plus longs mémoires, ce qui a permis d’identifier :
- La plus longue thèse du Québec. C’est l’Université de Montréal qui détient le record. Déposée au département de didactique en 2011, Développement et évaluation d’un environnement informatisé d’apprentissage pour faciliter l’intégration des sciences et de la technologie compte pas moins de 1 578 pages! Il faut cependant préciser que plus de 1 200 de ces pages sont des annexes.
- La deuxième plus longue thèse du Québec. Je prends la peine de souligner cette thèse de 1 562 pages parce que c’est la plus captivante que j’aie consultée! Publiée en 2000 au département de langue et de littérature françaises de l’Université McGill, la thèse de Sophie Marcotte est en fait d’une édition exhaustive de la correspondance de la romancière Gabrielle Roy avec son mari Marcel Carbotte. Je me suis souvent laissé prendre à en lire de grands extraits!
- Le plus long mémoire du Québec. Intitulé Élaboration d’un système d’information selon une approche sémiologique, il a été publié en 1990 à l’UQAC dans le cadre d’une maîtrise en gestion des petites et moyennes organisations. Il s’agit d’un mémoire en trois tomes comptant 744 pages. Dans le premier (168 pages), l’étudiant décrit sa démarche. Dans les deux suivants (217 et 359 pages respectivement), il décrit comment il a conçu et implanté un système informatique.
 Parmi les données que je colligeais, aussi, il y a la longueur des titres. Ici, les records sont les suivants :
Parmi les données que je colligeais, aussi, il y a la longueur des titres. Ici, les records sont les suivants :
- Le doctorat au titre le plus long : Stress maternel prénatal et développement précoce : données de naissance, attention et sécrétion cortisolaire à trois mois. Association entre le stress maternel prénatal, l’âge gestationnel et le poids de naissance du bébé : une analyse d’études prospectives. Association entre le stress maternel prénatal, l’attention/éveil et la sécrétion cortisolaire de l’enfant à trois mois. 378 caractères. C’était en 2012 au département de psychologie de l’Université Laval.
- Le mémoire au titre le plus long. Ici encore, la palme revient à l’Université Laval (maîtrise en physiologie-endocrinologie [2006]) : Effets d’un antioxydant, le tempol, sur les actions métaboliques et vasculaires de l’insuline chez le rat insulino-résistant avec un surplus de poids. Effets de l’insuline sur le transport du glucose dans le muscle squelettique, la réactivité vasculaire, l’expression des protéines eNOS, le stress oxydatif et les effets hémodynamiques régionaux. 345 caractères.
- Les doctorats aux titres les plus courts. Au pluriel, car nous avons ici une tripe égalité en tête. Trois thèses sont remarquables par leurs titres à la fois « punchés » et intriguants. 14 caractères seulement :
-
Agnostic Bayes (Université Laval, informatique, 2015)
-
Yours, vaguely (Concordia, Humanities, 1994)
-
Rétromarketing (UQAM, administration, 2013)
-
- Les maîtrises aux titres les plus courts. Trois maîtrises ont des titres qui ne comptent que quatre (4) caractères! Dans tous les cas, il s’agit de mémoires en études anglaises à l’Université Concordia : Cusp (2016), Jade (1993) et Work (2006). Il s’agit en fait d’œuvres de fiction, ce qui explique ces titres très brefs. Des 49 maîtrises de mon échantillon dont les titres comptent moins de 10 caractères, 41 sont des mémoires de ce département.
Un dernier exercice, enfin. Je comptais aussi le nombre d’octets des PDF que je téléchargeais. Ici, ma curiosité a été piquée par le plus gros document qui se retrouvait carrément dans une classe à part avec près de 2 gigaoctets (alors que la moyenne des mémoires ne « pèse » que 8,8 Mo).
En allant le consulter, j’ai découvert ce qui est peut-être le plus beau mémoire du Québec. Avec une forme qui tend vers le roman graphique, le « mémoire dessiné » de Marie-Jeanne Jacob a été publié en 2014 au département d’Art Education de Concordia. Il vaut le coup d’œil.
Étape 3 – Visualisations
Mais ce que je souhaitais surtout faire, avec cet exercice, c’était de reproduire l’excellent travail de Marcus Beck, évoqué ci-dessus, notamment, ses magnifiques graphiques sur le nombre de pages des thèses et mémoires par département à son université :
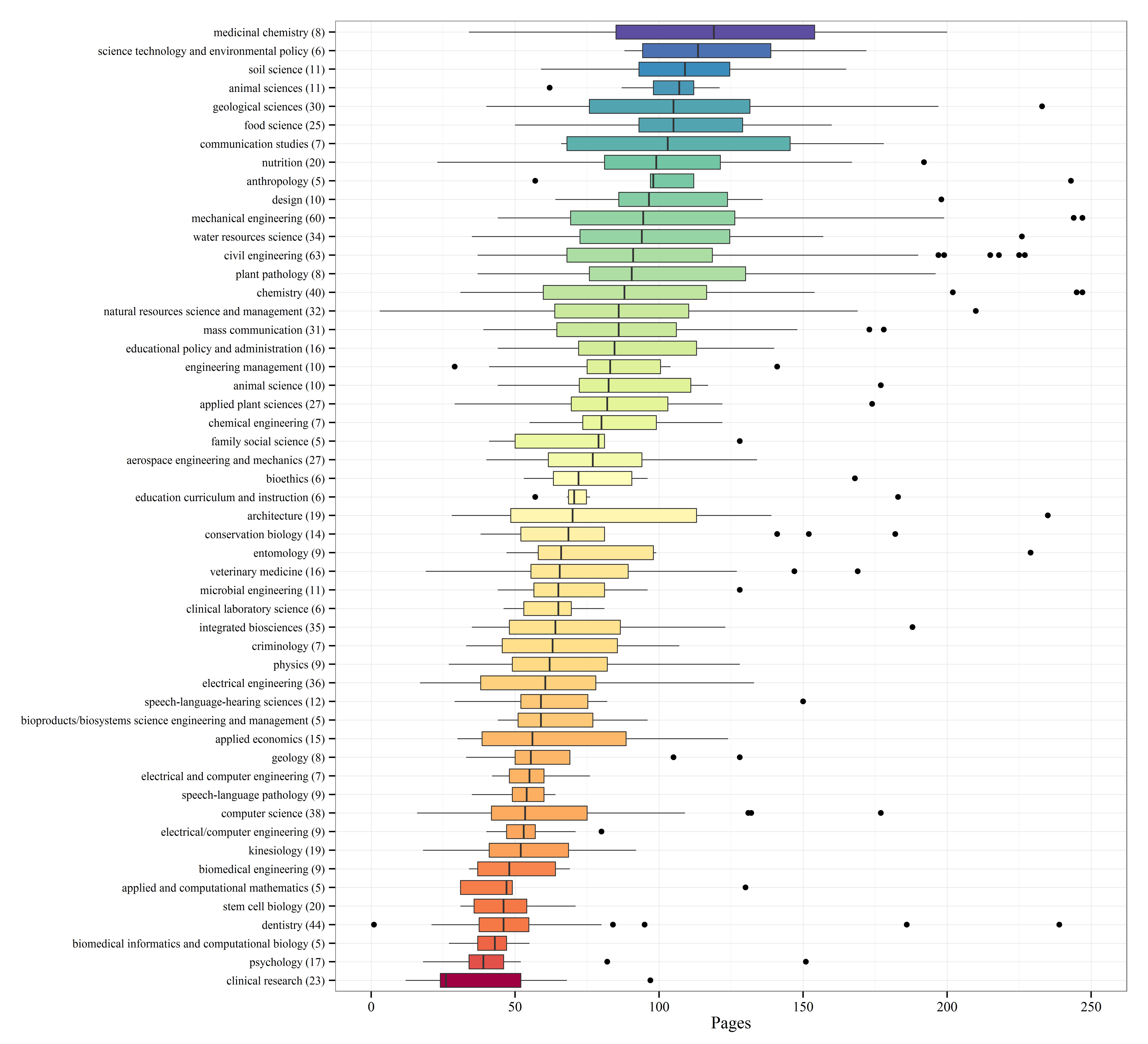
Longueur des mémoires par département à l’Université du Minnesota (2009-2014)
Pour lui, c’était simple. Il ne s’intéressait qu’à une seule université. Les départements étaient ainsi faciles à identifier et à utiliser comme base pour effectuer des regroupements.
Dans mon échantillon, en revanche, j’ai 13 universités. En outre, sur les nombreuses décennies que je couvre, des départements, des programmes ou des profils ont pu être créés ou encore modifiés, voire éliminés, à la faveur de refontes administratives. Sans compter qu’il peut y avoir plusieurs façons d’écrire un nom de département: en anglais, en français, avec le mot «département» au début ou non, avec ou sans erreur. Bref, pour toutes ces raisons, mon échantillon comprend pas moins de 687 départements, programmes ou profils différents!
Ainsi, par exemple, les thèses et mémoires en mathématiques ont pu être réalisés dans l’un ou l’autre des départements suivants :
- Mathématiques et informatique appliquées (n = 124)
- Mathématiques et génie industriel (n = 5)
- Mathématiques de l’ingénieur (n = 29)
- Mathématiques appliqués (sic) (n = 1)
- Mathématiques appliquées (n = 37)
- Mathématiques (n = 403)
- Mathematics and Statistics (n = 165)
- Mathematics (n = 73)
Je devais donc uniformiser ces départements, une uniformisation que j’ai effectuée en m’inspirant de la Classification révisée des domaines scientifiques et techniques de l’OCDE (2007).
Cette classification regroupe les domaines du savoir en six grandes catégories :
- Sciences exactes et naturelles (maths, physique, bio, par exemples)
- Sciences de l’ingénieur et technologiques (génie)
- Sciences médicales et sanitaires (médecine, nursing, etc.)
- Sciences agricoles (agronomie, sciences vétérinaires, notamment)
- Sciences sociales (psychologie, droit, administration, par exemples)
- Sciences humaines (histoire, langues, philosophie, etc.)
J’en ai ajouté une septième : les programmes personnalisés, autrement inclassables.
J’ai ensuite placé chacun de mes 687 départements ou programmes dans l’une ou l’autre de ces sept grandes catégories, que j’ai ensuite découpées en un peu plus de 100 disciplines, toujours en suivant la classification de l’OCDE. Cela donne la répartition suivante, un tableau fascinant de la production québécoise aux cycles universitaires supérieurs du dernier quart de siècle :
Cette répartition a facilité le travail de visualisation qui allait suivre. J’ai ainsi pu reproduire des graphiques équivalents à ceux de Marcus Beck à l’aide des modules python pandas, matplotlib et seaborn. Voici, par exemple, le graphique pour les maîtrises. Elles sont classées en fonction de la médiane du nombre de pages par discipline :
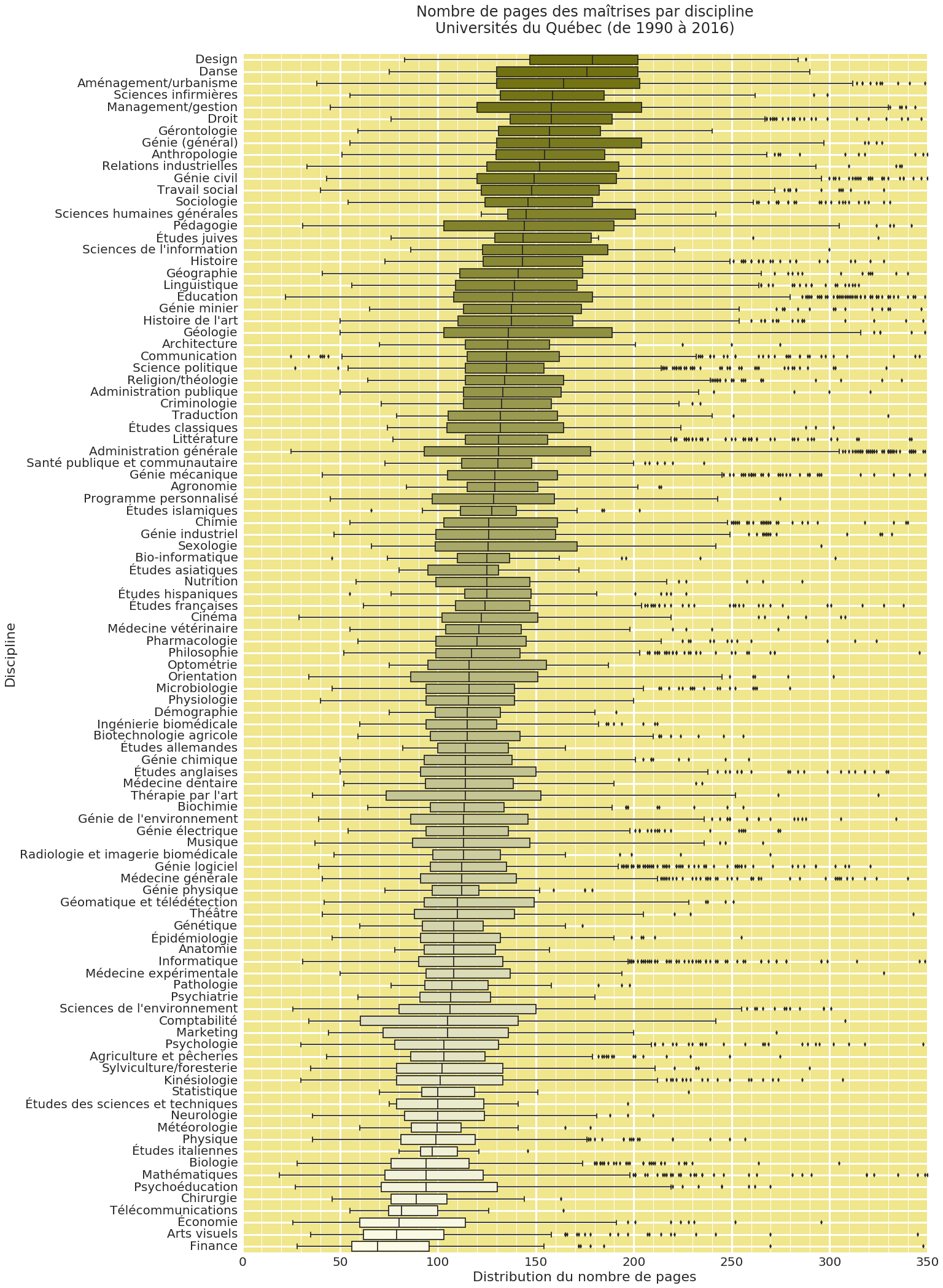
J’ai réalisé une série de visualisations qui permettent de répondre aux questions suivantes :
- Quelles disciplines produisent les thèses les plus longues? (Divulgâcheur: c’est en droit, avec une médiane de 459 pages!!!)
- Et les plus courtes?
- Est-ce que le classement est le même pour les mémoires de maîtrise?
- Et puis, dans quelle université les doctorants sont-ils les plus prolixes? (C’est dans la mienne, avec une médiane de 269 pages)
- Et qu’en est-il pour les étudiants à la maîtrise?
Pour ne pas allonger indûment ce billet, j’ai placé les graphiques, ma démarche détaillée pour les réaliser, ainsi que mes données brutes, dans ce répertoire Github. Bonne lecture et vive la science!

Bonjour,
Votre texte est intéressant, mais la mention de la plus courte thèse mérite une revérification. Le texte mentionné est en fait un mémoire doctoral en vue du titre de D. Psy, soit un diplôme associé à la pratique professionnelle de la psychologie clinique. Ce n’est pas un doctorat ni une thèse au sens Ph.D associé à des thèses autrement plus touffue.
Merci, M. Carbonneau, d’avoir relevé ce fait. J’avais téléchargé le document PDF, mais n’avait pas reconnu qu’il s’agissait d’un mémoire doctoral. J’avais exclu les essais de troisième cycle que je pouvais identifier (ils ne sont pas toujours faciles à repérer). Je vais aussi exclure les mémoires doctoraux. Bonne année 2017!
Vous écrivez au sujet du document https://papyrus.bib.umontreal.ca/xmlui/handle/1866/9049
(qui devrait plutôt être référencé par http://hdl.handle.net/1866/9049)
« Le document PDF ne compte que 11 pages seulement. Mais quand l’on ouvre et qu’on lit la table des matières, on constate qu’il devrait en réalité faire plus de 78 pages. En fait, le PDF ne contient que les pages liminaires du doctorat. Où est le reste? Mystère. »
Il y a une note à cet URL précis qui dit: « La version intégrale de cette thèse est disponible uniquement pour consultation individuelle à la Bibliothèque de musique de l’Université de Montréal (www.bib.umontreal.ca/MU). » Voilà donc où est le reste…
Enfin comme il est stipulé sur le site, pour la collection des thèses et mémoires en musique (http://hdl.handle.net/1866/2968):
Cette collection contient:
•Les fiches signalétiques des thèses et mémoires des étudiant(e)s de la Faculté de musique de l’Université de Montréal déposé(e)s entre le 1er octobre 2009 et le 1er novembre 2014. Pour ces documents, une version complète est disponible pour consultation individuelle à la Bibliothèque de musique de l’Université de Montréal (http://www.bib.umontreal.ca/MU).
• La version intégrale des thèses et mémoires des étudiant(e)s de la Faculté de musique de l’Université de Montréal (composition et musicologie) déposés après le 1er novembre 2014 ou encore une version tronquée des éléments pouvant aller à l’encontre du respect des droits d’auteur et, s’il y a lieu, un lien vers une version plus complète de la thèse ou du mémoire en vue d’une diffusion restreinte à la communauté UdeM.
***
Cette décision fût prise à l’origine par les responsables de la Faculté pour ne pas enfreindre le droit d’auteur, notamment dans le cas des thèses et mémoires en composition. Cette position a depuis été revue.
En espérant avoir pu élucider votre mystère….
Merci, Mme Vézina, d’avoir pris le temps de m’écrire ce commentaire! C’est apprécié! J’ai fait référence à votre explication dans mon texte. Bonne année 2017! 🙂
Suggestions de démarches alternatives/complémentaires (que vous avez peut-être considérées; j’avoue ne pas être allée voir le détail sur votre GitHub):
1. Interroger en z39.50 les catalogues de bibliothèques (ex. à l’UdeM nos paramètres d’interrogation z39.50 sont décrits ici: http://www.bib.umontreal.ca/aide-atrium/) et extraire ainsi toutes les notices MARC de thèses et mémoires (ici à l’UdeM on a une chaîne de caractères unique dans un champ MARC donné pour identifier qu’il s’agit d’une thèse ou d’un mémoire. Cette chaîne est repérable en cherchant dans tous les index: @attr 1=1016 « TheseUdeM », ou par ex. pour une seule année: (@and @attr 1=1016 « TheseUdeM » @attr 1=30 « 1950 »)). Le format MARC étant plus ou moins facile à consulter et manipuler, un convertisseur gratuit tel MarcEdit vous permettra de faire des transformations en lot vers des formats MARCXML ou encore en texte plus aéré (reproduit ci-après).
Ex. d’une notice MARC:
01003cam 22002651 4500001001000000003000600010005001700016008004100033035002100074035001900095035001300114040002200127090002900149090003200178100002600210245021200236260005100448300001100499502005200510610005400562650004100616650003800657730002800695793001400723000589358CaQMU20111211191334.0821027s1950 quc fre x a(OCoLC)8691659819 aCaQMUb10084524 a79012169 aCaQMUbfrecCaQMU0 aHV/13/U54/1950/v.002bTS0 aHV/13/U54/1950/v.002bSSc21 aBeaulieu, Marguerite.13aLa clinique d’aide à l’enfance — étude descriptive du fonctionnement actuel de la Clinique d’aide à l’enfance, attachée à la Cour des jeunes délinquants de Montréal, et des services qu’elle a rendus.0 a[Montréal] :bUniversité de Montréal,c1950 a106 f. aThèse (M.A.) — Université de Montréal, 195026aClinique d’aide à l’enfance, Montréal, Québec. 6aDélinquance juvénilexPrévention. 0aJuvenile delinquencyxPrevention.0 aThèse. Service social. aTheseUdeM
Ex. une fois convertie pour plus de lisibilité:
=LDR 01003cam 22002651 4500
=001 000589358
=003 CaQMU
=005 20111211191334.0
=008 821027s1950\\\\quc\\\\\\\\\\\\\\\\\fre\x
=035 \\$a(OCoLC)869165981
=035 9\$aCaQMUb10084524
=035 \\$a79012169
=040 \\$aCaQMU$bfre$cCaQMU
=090 0\$aHV/13/U54/1950/v.002$bTS
=090 0\$aHV/13/U54/1950/v.002$bSS$c2
=100 1\$aBeaulieu, Marguerite.
=245 13$aLa clinique d’aide à l’enfance — étude descriptive du fonctionnement actuel de la Clinique d’aide à l’enfance, attachée à la Cour des jeunes délinquants de Montréal, et des services qu’elle a rendus.
=260 0\$a[Montréal] :$bUniversité de Montréal,$c1950
=300 \\$a106 f.
=502 \\$aThèse (M.A.) — Université de Montréal, 1950
=610 26$aClinique d’aide à l’enfance, Montréal, Québec.
=650 \6$aDélinquance juvénile$xPrévention.
=650 \0$aJuvenile delinquency$xPrevention.
=730 0\$aThèse. Service social.
=793 \\$aTheseUdeM
En fonction des pratiques de catalogage des différentes institutions et à travers les années vous obtiendrez vraisemblablement, dans la zone 300, sous-zone « a », le nombre de pages.
Ex.:
=300 \\$ax, 125 f.
=300 \\$a2 v. (cclxi, 173 f.) :$bill.
=300 \\$axxx, 117 f. :$bgraph.
=300 \\$axviii, 112, [9] f. :$bgraph.
=300 \\$ax, 120, [1] f.
Il est ensuite aisé d’écrire un script avec le language de votre choix (Perl, Python, al.) pour extraire cette information et faire les additions des pages liminaires (en additionnant les sections en chiffres romains et arabes). La description de la syntaxe devant être utilisée dans cette zone est décrite ici: http://www.marc21.ca/MaJ/BIB/B300.pdf
Vous aurez invariablement quelques erreurs de chiffres romains qui proviennent ou de l’auteur, ou du catalogueur (exemples: xiiii, xlx, xlxv) et quelques limites: ex. parfois « 2 v. » pour 2 volumes sans que le nb de pages ne soit spécifié. Celà dit ceci constitue une bonne estimation. C’est une approche que j’ai moi-même employée pour estimer le nombre de pages à numériser dans le cadre d’éventuel projets de numérisation de ce type de document.
2. Beaucoup d’universités ont abandonné le dépôt papier des thèses et mémoires au cours des dernières années pour aller vers un dépôt électronique.
La plupart de ces documents sont versés dans des dépôts institutionnels et les schémas de métadonnées employées pour décrire ces documents ne comportent pas toujours un élément d’information concernant le nombre de pages. Il peut y avoir ou non une notice également versée au catalogue (automatiquement ou comportant des enrichissements).
À l’UdeM, les thèses et mémoires sont déposés en format électronique depuis 2009 (et plusieurs projets de numérisation rétrospective sont venus grossir le nombre de documents électroniques disponibles) et ne font pas l’objet d’une notice en format MARC. Dans ce cas il peut être intéressant d’interroger en OAI-PMH le dépôt institutionnel pour avoir l’ensemble des thèses et mémoires (plus d’informations ici: https://papyrus.bib.umontreal.ca/xmlui/page/interrogation-a-distance):
On peut lister uniquement les identifiants des documents du grand ensemble « Thèses et mémoires électroniques de l’Université de Montréal »
https://papyrus.bib.umontreal.ca/oai/request?verb=ListIdentifiers&metadataPrefix=etdms&set=col_1866_2621
On peut ensuite obtenir les métadonnées bibliographiques en divers format (ici en etdm) pour chaque document en reprenant son identifiant (ex.: oai:papyrus.bib.umontreal.ca:1866/10306):
https://papyrus.bib.umontreal.ca/oai/request?verb=GetRecord&metadataPrefix=etdms&identifier=oai:papyrus.bib.umontreal.ca:1866/10309
[Vous remarquerez que la plupart des universités canadiennes qui versent leurs thèses à la Bibliothèque nationale de Canada se conforme au format ETDM *et* y ont ajouté une extension pour y faire inscrire le nom du fichier .pdf principal de la thèse ou du mémoire (voir contenu de l’élément obtenu dans la requête plus haut)]
Plus intéressant, on peut obtenir la structure des composantes du document en OAI-ORE:
https://papyrus.bib.umontreal.ca/oai/request?verb=GetRecord&metadataPrefix=ore&identifier=oai:papyrus.bib.umontreal.ca:1866/10309
Et donc le lien direct vers le ou les fichiers de la thèse (description « ORIGINAL »), ex.: rdf:about= »https://papyrus.bib.umontreal.ca/xmlui/bitstream/1866/10309/2/Kassir_Nastya_2012_these.pdf »>
ou encore avoir à la fois les métadonnées et le document en METS:
https://papyrus.bib.umontreal.ca/oai/request?verb=GetRecord&metadataPrefix=mets&identifier=oai:papyrus.bib.umontreal.ca:1866/10309
Le nombre de pages peut ensuite être extrait des fichiers PDF avec une méthodologie semblable à celle que vous avez employée. Un programme maison d’interrogation et d’extraction des fichiers PDF devra encadrer le tout.
Merci pour ce long commentaire! Tous les détails qu’il contient sont précieux! 🙂
Pardon d’avoir tant tardé à y répondre. Le début de session a été intense et je ne suis pas retourné voir mon blogue assez souvent…
J’ai demandé, justement, les données de BAC, mais n’ai jamais obtenu de réponse. Je devrai revenir à la charge!