Cotes d’écoute de l’information: «making of»
Voici la recette que j’ai suivie pour faire mon billet sur l’écoute de l’information télévisée.
C’est une recette en quatre étapes:
- Étape 1 : Cueillette des données
- Étape 2 : Traitement des données
ÉTAPE 1.1 – CUEILLETTE DES DONNÉES : EXTRACTION DES URL
Les cotes d’écoute sont mesurées par Numeris, nouveau nom de BBM (ex Bureau of Broadcast Measurement). Les données de Numeris ne sont pas gratuites. C’est son pain et son beurre.
 L’entreprise publie néanmoins chaque semaine un document qui peut nous servir de point de départ. Il s’agit du palmarès hebdomadaire des 30 émissions les plus regardées au Québec francophone.
L’entreprise publie néanmoins chaque semaine un document qui peut nous servir de point de départ. Il s’agit du palmarès hebdomadaire des 30 émissions les plus regardées au Québec francophone.
Chaque semaine, donc, Numeris rend publique une liste des 30 émissions les plus regardées avec, entre autres:
- le titre de l’émission
- son diffuseur
- sa cote d’écoute (en milliers de téléspectateurs)
Chaque palmarès hebdomadaire est un document PDF. Les données les plus anciennes remontent au 31 août 2009 (il y a une liste datée du 4 janvier 2009, mais les données sont en fait pour le 4 janvier 2010).
OK. On fait quoi avec ça?
Le format PDF est le cauchemar des journalistes de données depuis des années. Ici, il y a un document PDF par semaine. 52 semaines par année. Environ 5 ans de données. Donc un peu plus de 250 documents PDF à télécharger.
250 téléchargements un par un? Ça va nous prendre des heures! À moins qu’on ne se serve de deux outils:
- une extension Chrome appelée simplement Scraper.
- la commande UNIX wget.
Le premier outil, Scraper, est une extension du logiciel fureteur Chrome. Elle prend la forme d’une commande qui s’ajoute au menu contextuel. On y voit une sympathique icône de grattoir à peinture avec la mention « Scrape similar… »
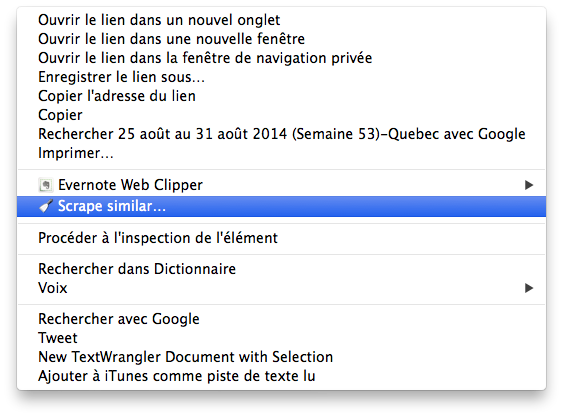
On va se servir de ce grattoir virtuel pour aller chercher les URLs des quelque 250 fichiers PDF qui nous intéressent. Pour commencer, donc, on place notre curseur sur le premier hyperlien qu’on voit sur la page du Palmarès des émissions les plus regardées, à savoir le lien vers le fichier PDF de la semaine la plus récente:

On clique dessus avec le bouton de droite (CTRL-clic sur Mac) et, dans le menu contextuel, on sélectionne « Scrape similar… ». Une fenêtre surgit alors. C’est notre outil qui nous informe qu’il a trouvé un URL pour nous.
Il nous donne le texte de l’hyperlien (colonne «Link», semaine de mesure des cotes d’écoute, ici: du 25 au 31 août 2014) et l’adresse web correspondante (colonne «URL», c’est-à-dire l’adresse du fichier PDF de la liste des 30 émissions les plus regardées cette semaine-là.)
 Fort bien. Mais il serait beaucoup plus intéressant de recueillir d’un seul coup les URL des 15 semaines affichées sur cette page. On peut y parvenir en jouant avec le code Xpath dont notre outil se sert.
Fort bien. Mais il serait beaucoup plus intéressant de recueillir d’un seul coup les URL des 15 semaines affichées sur cette page. On peut y parvenir en jouant avec le code Xpath dont notre outil se sert.
Si on examine la partie gauche de la fenêtre Scraper, on voit une section appelée «Selector».
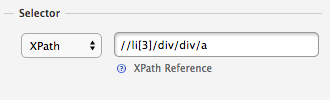
On y voit une expression écrite en langage XPath:
//li[3]/div/div/a
Ce que nous dit cette commande, c’est que Scraper examine le code HTML de la page où nous nous trouvons et qu’il s’arrête à la troisième balise <li> qu’il rencontre. Ensuite, à l’intérieur de cette balise, il regarde ce qui se trouve à l’intérieur d’une première balise <div>, puis d’une seconde, puis il retourne le contenu de la balise <a> qui s’y trouve.
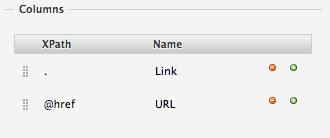
La section «Columns», juste en dessous, nous dit plus précisément que ce qui est retourné, c’est le contenu de l’élément <a> (Scraper le met dans la colonne «Link») et le contenu de l’attribut href contenu dans cet élément (que Scraper met dans la colonne «URL»).
On peut demander à Scraper de nous retourner les 15 URL présents dans cette page en modifiant la commande XPath comme suit:
//li[position()>2]/div/div/a
Ce qui se produit alors, c’est que Scraper effectue la même cueillette que tout à l’heure, mais pour toutes les balises <li> après la deuxième (à partir de la troisième, donc).
Eurêka! Ça marche:
 On peut ensuite exporter notre liste de 15 URL sous forme de tableur directement dans notre compte Google Drive en cliquant sur le bouton «Export to Google Docs…» situé en bas, à droite.
On peut ensuite exporter notre liste de 15 URL sous forme de tableur directement dans notre compte Google Drive en cliquant sur le bouton «Export to Google Docs…» situé en bas, à droite.
Comme Numeris ne permet l’affichage que de 15 URL à la fois, il faut répéter l’opération plusieurs fois (18 fois pour être exact). Ce n’est pas trop long. On se retrouve à la fin avec 18 fichiers. J’en ai moins dans la capture d’écran ci-dessous, car lorsque j’ai effectué cette opération, le 3 septembre, c’était sur l’ancien site de BBM et il affichait la liste des URL pour une année entière. C’était moins fastidieux.

Il suffit ensuite de:
- réunir tous ces fichiers,
- de ne conserver que la colonne des URL,
- de l’exporter sous format texte (txt).
Voici la liste des 261 URL que j’avais obtenue il y a quelques jours. Les URL sont différents, puisque j’avais glané le site bbm.ca.
Pourquoi sous format txt? Parce que c’est ce qu’exige le second outil dont on va se servir dans cette étape de cueillette.
ÉTAPE 1.2 – CUEILLETTE DES DONNÉES : TÉLÉCHARGEMENT AUTOMATISÉ AVEC wget
La commande UNIX wget permet de télécharger directement des fichiers sur le web de différentes manières. L’une des plus intéressante, c’est de lui fournir une liste d’URL en format texte, et wget télécharge les fichiers associés avec une rapidité étonnante.
J’ai entré la commande suivante dans Terminal:
wget -i ecoute-tele.txt
Et en 40 secondes, j’avais les 261 documents PDF que je voulais sur mon bureau (la capture d’écran ci-dessous en montre 262, car j’avais un doublon)!
Wow! J’étais très impressionné!

Mais le travail n’est pas terminé. Il y a encore tout un boulot de traitement des données à effectuer.
ÉTAPE 2.1 – TRAITEMENT DES DONNÉES : EXTRACTION DES PDF
Il existe différents outils qui permettent de transformer des documents PDF dans un format plus facile à traiter quand on fait du journalisme de données? Le logiciel Acrobat, d’Adobe, est l’un de ceux-là. Mais il n’est pas gratuit…
![]() ScraperWiki offre depuis quelque temps un service d’extraction de données contenues dans des fichiers PDF. Il faut cependant que nos PDF aient été produits directement à partir d’un logiciel de traitement de texte ou d’un tableur. S’ils ont été produits à partir d’images, ScraperWiki sera incapable d’en extraire les données, car il faudra préalablement faire de la reconnaissance optique des caractères (OCR) sur le fichier. Dans ces cas, Acrobat est préférable.
ScraperWiki offre depuis quelque temps un service d’extraction de données contenues dans des fichiers PDF. Il faut cependant que nos PDF aient été produits directement à partir d’un logiciel de traitement de texte ou d’un tableur. S’ils ont été produits à partir d’images, ScraperWiki sera incapable d’en extraire les données, car il faudra préalablement faire de la reconnaissance optique des caractères (OCR) sur le fichier. Dans ces cas, Acrobat est préférable.
Heureusement, les PDF des 30 émissions les plus regardées sont traitables par ScraperWiki. Il faut d’abord les réunir en un seul et même document, ce qui nous donne un seul document PDF de 262 pages. Cela est cependant trop lourd pour ScraperWiki. On peut alors le briser en cinq documents d’environ 50 pages chacun, des bouchées plus faciles à avaler pour le service gratuit.
On commence par choisir l’option « Extract tables » dans l’écran d’accueil:

Dans l’écran qui suit, on téléverse ensuite notre premier PDF. ScraperWiki extrait tous les tableaux qu’il contient et les transforme en format utilisable par un logiciel tableur. L’opération prend quelques minutes tout au plus. Une fois l’extraction terminée, il ne faut pas oublier de télécharger le résultat en format Excel sur son ordi, avant de procéder à l’extraction du document PDF suivant.

Une fois nos cinq PDF traités, on a cinq documents .xlsx sur notre ordi. Chacun comprend une cinquantaine de feuilles, une par semaine de données. Chaque feuille contient donc nos 30 émissions les plus écoutées cette semaine-là… Une trentaine de lignes, ou un peu plus… et beaucoup de cochoncetés…
ÉTAPE 2.2 – TRAITEMENT DES DONNÉES : NETTOYAGE
Il y a un gros ménage à faire dans ces fichiers. Tout d’abord, il faut uniformiser les colonnes. Dans plusieurs cas, ScraperWiki a mal organisé les entêtes de colonnes. Il a aussi placé le contenu dans des cellules fusionnées qui ont deux ou trois colonnes de largeur. Voici un exemple:
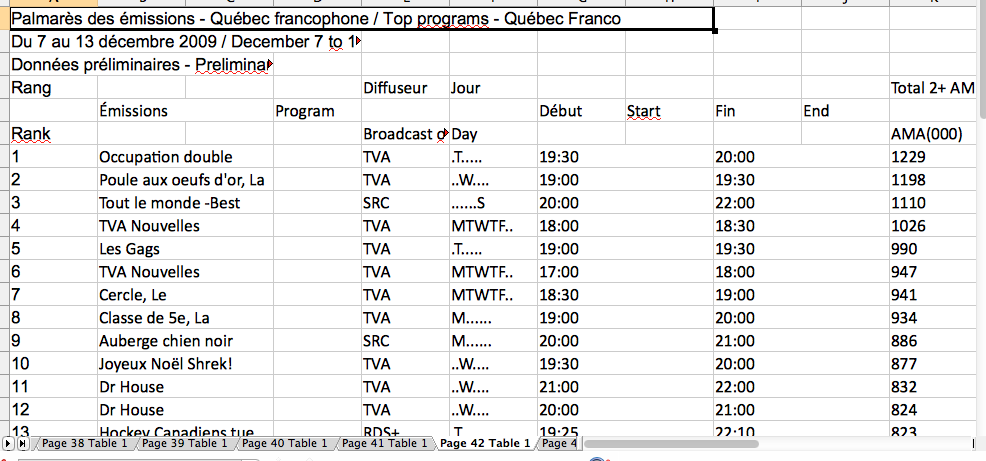
Ce n’est heureusement pas trop compliqué à arranger. Juste un peu long (il faut vérifier les 261 feuilles). Après nettoyage, on a un tableau bien propre et, ce qui est plus important, toutes nos feuilles ont une structure identique:

On peut maintenant créer une nouvelle feuille afin de réunir toutes les infos contenues dans les 261 feuilles en un seul tableau. Ce sera notre base de données.
Dans cette nouvelle feuille, on va reproduire les colonnes des tableaux de BBM, bien sûr (nom de l’émission, diffuseur, cote d’écoute, etc.), mais on va aussi en ajouter d’autres:
- la date du début de la semaine de mesure,
- le mois,
- l’année,
- le numéro de ligne
- le numéro de feuille
Pourquoi a-t-on besoin du numéro de ligne et du numéro de feuille? C’est presque un système de «coordonnées», car la combinaison numéro de ligne et numéro de feuille est unique à chaque émission qu’on va ajouter à notre base de données. Le numéro de ligne, c’est simplement le rang de l’émission dans le palmarès d’une semaine donnée. Le numéro de feuille, c’est celui qui a été généré quand on a importé tous nos tableaux Excel dans un seul document (en fait, il est intitulé «Page»; Page 1, Page 2, Page 3, et ainsi de suite jusqu’à la Page 261):
![]()
Ces «coordonnées» vont nous aider à construire notre tableau. On commence par générer les numéros de feuille dans la colonne A. Il faut des numéros de 1 à 261, mais il en faut 30 de chacun: 30 «uns», suivis de 30 «deux», suivis de 30 «trois», etc. La formule suivante, placée à partir de la cellule A2, permet de le faire: =ENT((LIGNE()-2)/30)+1
On peut copier cette formule dans les quelque 7500 cellules en-dessous. Pour les numéros de ligne, placés dans la colonne B, on peut utiliser la formule suivante dans la cellule B2: =SI(B1<30;B1+1;1)
Pour nous aider à extraire les dates de chacun des palmarès, on peut ensuite créer une colonne C avec la formule suivante: =INDIRECT("'Page "&A2&" Table 1'.A$2")
La fonction INDIRECT permet de construire indirectement des formules en se servant du contenu d’autres colonnes. Ainsi, ici, on appelle la cellule A$2 de chacune de nos feuilles, dont le nom est toujours «Page X Table 1», où X varie de 1 à 261. La formule INDIRECT permet de nous servir du contenu de la colonne A pour changer la valeur de X.
Le résultat est une chaîne de caractères, comme celle-ci: «Du 14 au 20 janvier 2013 / January 14th to 20th, 2013». On va s’en servir pour extraire la date du début de chaque semaine de mesure.
Commençons par le jour, qu’on va placer dans la colonne D. On commence par vérifier si notre semaine commence par le 1er. Dans ce cas, la date est «1», autrement, elle est constituée des 4e et 5e caractères de notre chaîne, auxquels on applique la fonction SUPPRESPACE si cette date ne contient qu’un chiffre:
=SI(STXT(C2;4;3)="1er";1;SUPPRESPACE(STXT(C2;4;2)))
Ensuite, le mois, colonne E. C’est compliqué, car il y a des semaines qui chevauchent des mois: («Du 28 janvier au 3 février 2013 (…)», par exemple). Dans ces cas, le nom du mois ne commence qu’au 6e, 7e ou 8e caractère de notre chaîne (selon que la date est à un chiffre, à deux, ou «1er»). Dans les autres cas («Du 14 au 20 janvier 2013 (…), par exemple»), le nom du mois commence entre le 11e et le 14e caractère, selon les cas. Il faut donc prévoir tous ces cas, et extraire le mois au complet, peu importe sa longueur (du plus court, mai, au plus long, septembre), ce que cette formule réussit à faire. Il y a peut-être moyen qu’elle soit plus courte, mais je n’ai pas trouvé:
=SI(TROUVE("au";C2)<10;SI(STXT(C2;4;3)="1er";STXT(C2;TROUVE(" ";C2;11)+1;TROUVE(" ";C2;14)‑TROUVE(" ";C2;11));STXT(C2;TROUVE(" ";C2;10)+1;TROUVE(" ";C2;14)‑TROUVE(" ";C2;10)));STXT(C2;TROUVE(" ";C2;4)+1;TROUVE(" ";C2;7)‑TROUVE(" ";C2;4)))
Il faut ensuite convertir le nom du mois en nombre:
=MOIS(DATEVAL(E2&"1"))
L’année, c’est plus simple, car toutes les chaînes de caractères se terminent par les quatre chiffres de l’année, qu’on extrait avec cette formule:
=DROITE(C2;4)
Dans les quelques cas où une semaine chevauche deux ans, il faut aller manuellement changer l’info sur la feuille et ajouter la mention «commence en 2013», pour la semaine du 30 décembre 2013 au 5 janvier 2014, par exemple. On peut ensuite assembler jour, mois et année ainsi: =DATEVAL(G2&"-"&F2&"-"&D2)
Ensuite, il suffit d’extraire les noms d’émission, de diffuseur et les cotes d’écoute correspondantes avec des formules qui se ressemblent. Voici celle pour les noms d’émission:
=SI(ESTNUM(CNUM(INDIRECT("'Page "&$A2&" Table 1'.$A$6")));INDIRECT("'Page "&$A2&" Table 1'.B$"&$B2+5);INDIRECT("'Page "&$A2&" Table 1'.B$"&$B2+6))
Elle comprend une condition, simplement parce que la disposition de l’information a changé au fil des ans dans les tableaux de BBM: certaines années, les tableaux ont une ligne de plus. Il n’y a que deux cas possible, donc une seule fonction SI(). Autrement, la formule va simplement extraire une cellule donnée dans une feuille donnée, en fonction des numéros de ligne et de feuille qu’on a préalablement indiqués aux colonnes A et B. La formule qui va chercher la cote d’écoute est précédée d’une fonction CNUM() pour s’assurer que la cote d’écoute soit intégrée à notre tableau comme un nombre.
Une fois qu’on a toutes nos données réunies en un seul tableau, il y a encore un peu de ménage à faire. On se rend compte, notamment, qu’il faut corriger des erreurs commises par BBM dans les dates. Dans l’exemple ci-dessous, on se rend compte qu’au début de 2012, les gens qui ont fait la saisie de données chez BBM on oublié de changer l’année et les premiers tableaux publiés en janvier 2012 sont encore libellés 2011.
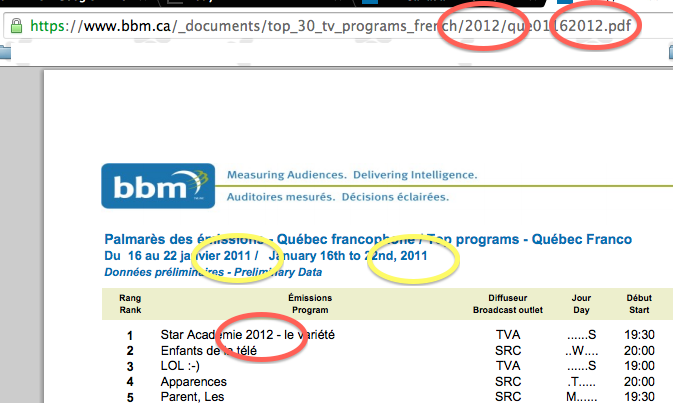
Il faut aussi uniformiser certains noms d’émission dont les noms ne sont pas consistants (La Facture avec majuscule et d’autres fois sans, J.E. parfois écrit JJ.EE., etc.) Ici, un petit tour par OpenRefine est essentiel.
Et voilà! On a un tableau final d’un peu plus de 7500 lignes, une base de données simple de l’écoute des émissions de télévision les plus populaires au Québec ces cinq dernières années, avec laquelle vous pouvez vous amuser.
Pour ma part, j’ai fait quelques graphiques sur Plot.ly, un service que j’aime de plus en plus, graphiques présentés ici.
