Les mots de la 40e législature («making-of»)
Voici, en trois étapes faciles, la recette pour glaner les débats de la 40e législature.
Première étape: les url
Il n’est pas possible de télécharger tous les débats de la 40e législature à partir du site de l’Assemblée nationale. L‘outil de recherche du Journal des débats de l’#assnat est bien fait et permet d’extraire les débats en fonction de plusieurs critères (le député, l’intervenant, la date, le sujet, notamment), mais pas ce qu’on cherche, à savoir TOUS les débats d’une même législature.
Il faut donc se fabriquer ses propres outils. On commence en demandant à l’outil de recherche de sortir toutes les pages des débats de la 40e législature. Cela donne 627 résultats, ce qui veut dire que les débats complets (en Commission parlementaire et au Salon bleu) des 18 mois du gouvernement Marois tiennent sur 627 pages web. Il faut donc glaner (scraper) chacune de ces pages.
Mais avant, il faut connaître les URL de ces 627 pages. Elles se trouvent dans les résultats de recherche. Pour se faciliter la vie, on peut demander un affichage de 100 résultats par page:
Cela donne sept pages de résultats. Comme chaque page n’a pas sa propre URL distincte, il faut les enregistrer toutes les sept en mode local avant de passer à l’étape suivante et leur donner des noms qui se suivent, comme assnat01.html, assnat02.html, etc.
Il faut maintenant écrire un court script qui glane ces sept pages et va y chercher les 627 URL qui nous intéressent. Eurêka! Nous avons nos 627 adresses web!

Deuxième étape: extraire le contenu
Il s’agit maintenant d’écrire un deuxième script qui ratisse chacune de ces 627 pages et qui en extrait le contenu.
On ne se contentera cependant pas de simplement extraire le contenu. On est des journalistes et on ne veut pas juste le quoi. On veut aussi le qui, le quand et le où.
On va donc associer chaque intervention à trois variables: intervenant (le «qui», en fait le nom du député), date (le «quand») et type (le «où», c’est-à-dire que l’intervention a été faite au Salon bleu ou en Commission parlementaire). Cela nous permettra de créer un fichier CSV avec quatre colonnes où, à chaque ligne, on saura qui parle, quand il ou elle parle, où et, surtout, ce qu’il ou elle dit. Une fois qu’on sait ce qu’on veut, on peut donc écrire notre second script.
Voici un aperçu du fichier CSV que l’on obtient :

Mais c’est un fichier assez gros. 84 341 lignes. Près de 33 mégaoctets. Pour alléger les étapes ultérieures, on peut décider d’exclure les débats en Commission parlementaire. On réduit alors notre fichier CSV à 53 712 lignes et un peu plus de 21 mégaoctets, une réduction substantielle de 35% (du nombre d’octets).
On peut ensuite traiter ce CSV avec Calc pour compléter les noms des élus et ajouter deux colonnes: l’une pour leur affiliation (par parti ou «neutre» dans les cas des intervenants neutres comme le président ou les vice-présidents de l’Assemblée nationale) et l’autre pour compter le nombre de caractères de chacune des interventions à l’aide de la fonction =nbcar.

On peut dès lors importer ce fichier dans les tables de fusion Google pour produire quelques visualisations intéressantes (voir résultats).
Troisième étape: analyser le contenu
Tout cela est très bien, mais n’oublions pas notre objectif initial: produire un nuage de mots.
On se rend vite compte qu’il s’en dit, des choses, à l’Assemblée nationale, même au cours d’un mandat très court comme celui du gouvernement Marois. Il s’en dit tellement, que d’analyser tout le contenu s’est avéré trop lourd pour un tableur comme Calc. Excel aurait autant de difficultés.
On doit donc séparer le contenu par parti. En fait, on peut simplement prendre notre CSV de tout à l’heure et en faire 4 copies: une pour le PQ, une pour le PLQ, une pour la CAQ et une pour QS. Dans chacune de ces copies, on ne conserve que le contenu de ce qui a été dit par les membre du parti correspondant. On se retrouve donc avec 4 fichiers CSV dont on peut changer l’extension à .txt pour qu’ils soient plus faciles à lire par notre prochain script.
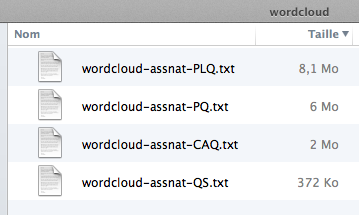
On le voit les fichiers sont quand même (sauf pour QS) d’une taille appréciable pour de simples fichiers textes. Il suffit ensuite d’écrire un script qui prend chacun de ces fichiers, met tout en minuscules et nettoie le texte pour produire une liste des mots de trois caractères ou plus. Ce script est si simple qu’on peut l’intégrer ci-dessous:
On peut ensuite jouer avec ces listes pour en faire ressortir l’essentiel.
En terminant, quelques liens si vous souhaitez aller plus loin:
- Les résultats.
- Les données brutes (les 4 fichiers appelés wordcloud-assnat-***.txt).
- Les données traitées (attention, il y a 6 onglets).
